контейнер, требования: должны быть определены внутренние типы value_type и T&, const T&, iterator и const iterator, а также кучу методов с соответствующими асимптотиками итератор - внутренний тип, должен быть у каждого контейнера и хотябы forward iterator std::forward_list - не контейнер, тк .size() работает за O(n)
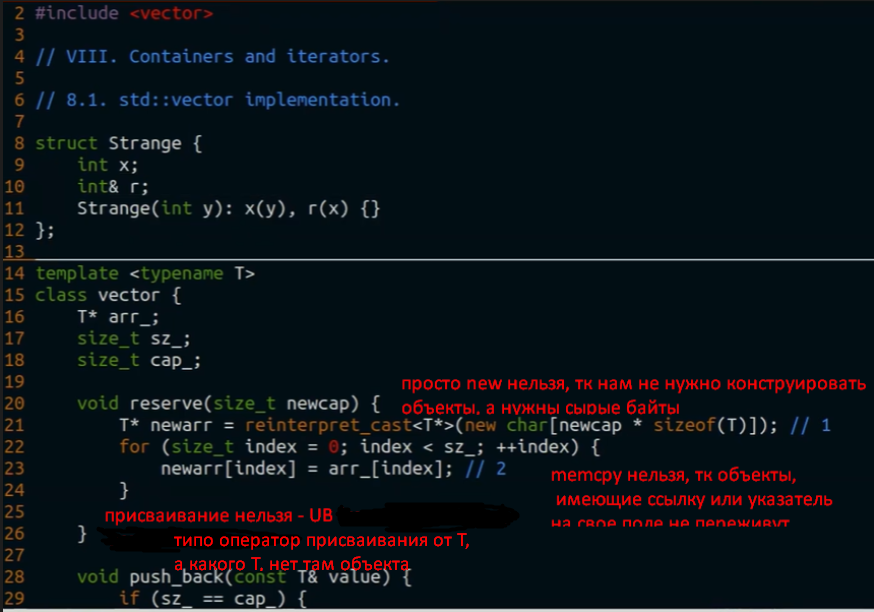 у оператора new, помимо стандартной формы new T(), есть new с параметром (поинтер)
у оператора new, помимо стандартной формы new T(), есть new с параметром (поинтер)
new(pointer) T(arr[i]) - placement new - вызвать конструктор данного типа по данному адресу
отличие push_back от emplace_back - emplace_back это метод, который принимает не объект T, а аргументы, из которых создает T на месте
template <typename... Args>
void emplace_back(const Args&... args)
...
new (ptr) T(args)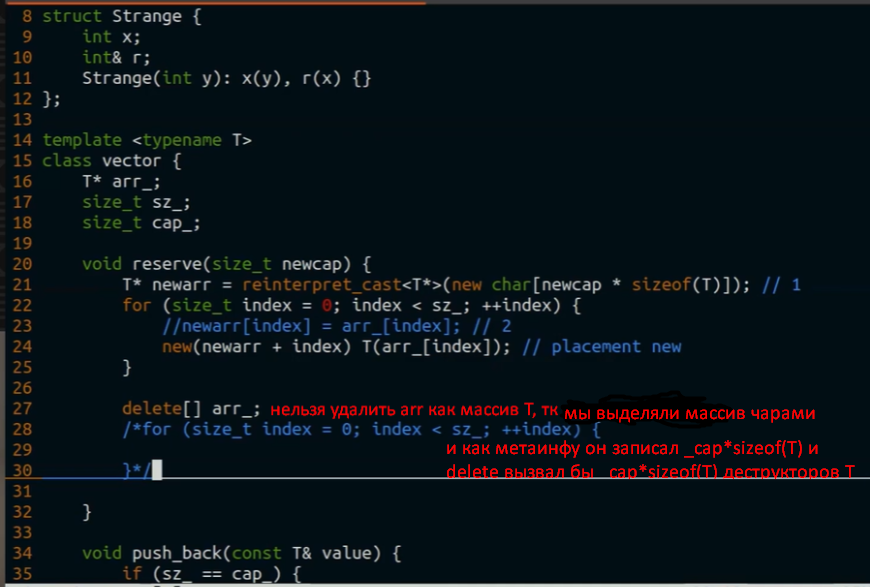 delete надо кастануть к char* и освободить память так
delete надо кастануть к char* и освободить память так
 конструктор T может кинуть исключения и тогда придётся удалить всё то, что мы успели скопировать
конструктор T может кинуть исключения и тогда придётся удалить всё то, что мы успели скопировать
инвалидация указателей
std::vector<int> v(10);
int* p = &v[5];
v.push_back(1); // pointer/reference invalidation
std::cout <<*p; - UBс ссылкой тоже самое будет
с std::vector<int>::iterator x = v.begin()+5; тоже UB!!!!!
нельзя ничего вставлять в вектор, а потом разыменовывать указатели на элементы вектора, которые были созданы до этого
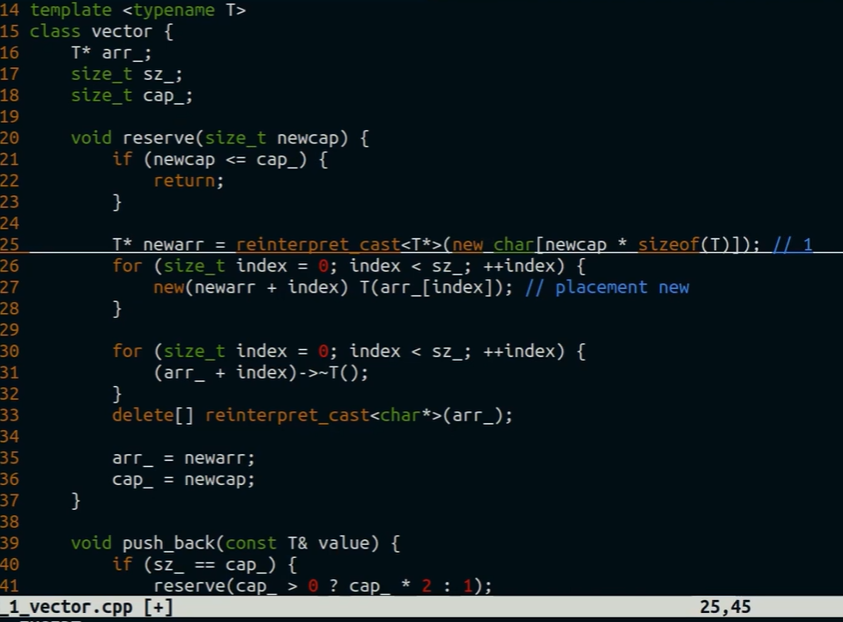
создание пустого вектора или дека не аллоцирует память
в векторе сначала пушится объект на новое реалоцированное место, а только потом происходит перекладывание всех старых объектов. это сделано для того, чтобы push_back(v[3]) не привёл к UB (все старые объекты разрушились и нужно запушить битую ссылку)
ассоциативные контейнеры
std::list - двусвязный список std::forward_list - односвязный список std::deque - двусторонняя очередь (умеет индексироваться и докладывать/вынимать из конца и начала) std::stack - некоторый интерфейс доступа к вектору. по умолчанию надстройка над деком std::priority_queue - посути куча. внутри по умолчанию хранит дек, но может и вектор
упорядочено хранить данные в красно-черном дереве: std::map - упорядочено хранит пары ключ-значение. отображение если в map обратится по несуществующему ключу, то он создаст значение с этим ключом и инициализирует его по умолчанию за O(logn), потому что map это красно-черное дерево .at() .find() .insert(pair<key, value>) .erase(key)
std::multimap как map, но умеет хранить несколько значений с одним ключом. нету [] и .at() есть .lower_bound(key) и .upper_bound(key)
std::set хранятся значения упорядочено нет [] и нет .at() std::multiset
std::unordered_map, std::unordered_set - хэш-таблицы. неупорядочено хранят данные, но поиск, вставка и удаление работают в среднем за О(1)
разница между амортизированной О(1) и в среднем О(1): амортизированная единица значит, что если много раз подряд что-то делать, то общее время/кол-во раз что это сделали будет стремится к 1 в среднем значит что зависит от входных данных. есть такие наборы данных, на которых всегда будет работать медленно
отличие deque от vector:
- имеет .push_front() и .pop_front()
- не инвалидирует указатели и ссылки при добавлении элементов
- нету .shrink_to_fit(), reserve(), и _capasity но итераторы в деке инвалидируются при добавлении, как и в векторе
в std::list, std::map, std::set ничего никогда не инвалидируется
std::stack
std::queue -- адаптеры над std::deque
std::priority_queue
стек и очередь можно сделать адаптерами над вектором и листом адаптер - обёртка над методами нижележащего типа или над своей структурой, главное, чтобы она поддерживала все нужные методы
std::stack
template<typename T, typename C = std::deque<T>>
если бы pop возвращал бы T, то мы бы не смогли избавиться от копирования, которое не всегда нужно
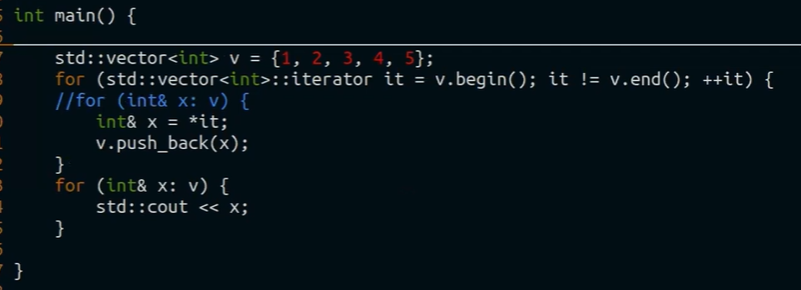
UB -> Segfault, тк мы не можем достигнуть v.end(), он меняется
но range-based for для stl вектора UB не даст, тк он запоминает изначальные .begin() и .end() и в их границах идёт
std::list
insert(iterator it, const T& value)- вставка за О(1),- нету индексов, нету []
erase(iterator it)- удаление за О(1)- push_back, push_front, pop_back, pop_front - O(1)
- .size() - O(1)
хоть работает гарантировано за О(1), это всё равно медленный контейнер, тк при каждом добавлении вызывает new
также ещё можно куски элементов удалять и вставлять за O(elements)
 std::sort над std::list - CE (std::sort подразумевает randomaccess итераторы, а в std::list - bidirectional)
.sort() листа использует mergesort (implementation defined, главное стабильная и за nlogn) и ему достаточно лишь forward итератора (логарифмическая сложность по памяти, тк в какойто момент времени нужно будет хранить logn указателей на куски, которые нужно смерджить)
.merge() - слить 2 отсортированных списка
.splice(it1, it2, it3) - вырезать кусок из одного списка и вставить в другой
O(to-from) если it1,it2 и it3 - разные листы
O(1) если это всё один лист
это все потому что size надо пересчитать
std::sort над std::list - CE (std::sort подразумевает randomaccess итераторы, а в std::list - bidirectional)
.sort() листа использует mergesort (implementation defined, главное стабильная и за nlogn) и ему достаточно лишь forward итератора (логарифмическая сложность по памяти, тк в какойто момент времени нужно будет хранить logn указателей на куски, которые нужно смерджить)
.merge() - слить 2 отсортированных списка
.splice(it1, it2, it3) - вырезать кусок из одного списка и вставить в другой
O(to-from) если it1,it2 и it3 - разные листы
O(1) если это всё один лист
это все потому что size надо пересчитать
отличие std::list от std::forward_list (C++11): в std::forward_list:
- forward iterator
- нету prev
- нету push_back и pop_back
- нету .size()
- вместо insert - insert_after
в std::list, как в std::map - под итератором на end() - фейковая нода. в фейковой ноде нет value и она связана с begin и end-1. в пустом листе одна фейковая нода (begin == end == fakenode)
std::map - упорядоченный ассоциативный массив “(const)ключ-значение”
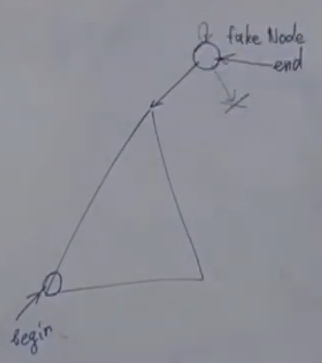

нельзя хранить объекты с одинаковыми ключами. при попытке вставить значение по ключу, который уже был, то вставки не произойдёт и вернётся итератор на то место, где уже был ключ
- insert(const std::pair<key, value>&) - вставка по ключу - возвращает std::pair<iterator, bool> iterator - то, куда вставили, bool - произошла ли вставка
- erase(const key&) - удаление по ключу erase(iterator) - удаление по итератору
- at(const key&) - получать ссылку на значение по ключу - находит элемент или кидает исключение. также есть константная версия, которая возвращает константную ссылку
- [const key&] - получать ссылку на значение по ключу. нет константной версии => у константного std::map нельзя вызывать []. если ключа такого нет, то создаётся новый ключ со значением по умолчанию - меняют std::map
- find(const key&) - find по ключу, возвращает итератор на найденный или end
- size_t count(const key&) - есть такой ключ или нет
- bool contains(const key&) - есть такой ключ или нет (C++20) это все работает за гарантированный O(logn)
if (auto it = m.find(1); it != m.end()) it->second = 2; (if с инициализацией C++17)
- lower_bound(key), upper_bound(key) - возвращают итератор, на наименьший элемент >=/> key
асимптотика инкремента итератора: O(logn) асимптотика обхода мапы: O(n)
next_permutation на std::map - CE, тк в какой-то момент вызовется *it1 = *it2, под итераторами std::pair<const key, value>, а присвоить const key ничего нельзя
std::set - std::map, в котором вместо пар хранятся просто ключи
- нет []
multimap - тоже нет [] - вместо них lower_bound и upper_bound
- equal_range(key) - возвращает пару итераторов на lower_bound и upper_bound - один спуск по дереву
map ~ set пар
std::unordered_map (C++11)
std::hash<int>() - функциональный объект для каждого типа свой. есть оператор()
std::hash<int>()() - стандартная хешфункция примененная к инту
стандартный хеш есть от всех стандартных типов
когда заводится unordered_map для ключей какого-то стандартного типа, то применяется std::hash от того типа
все операции работают за O(1) в среднем. среднее берется не по количеству выполненных операций, а по возможных входных данных. отличается от O(1) амортизированной тем, что вместо того, что при многочисленном повторении операции большинство операций будут O(1), может неповезти так, что все операции будут долгими, если подобрать неудачный набор ключей
размер таблицы: захардкоженая последовательность простых чисел (implementation defined). когда таблица заполняется, за линейное время происходит rehash можно размер задать через .reserve(n) (reserve вызывает rehash)
float load_factor() - метод, возвращающий отношение кол-ва лежащих ключей к размеру хештаблицы .max_load_factor() - возвращает float - число, при превышении которого происходит рехеш .max_load_factor(float) - устанавливает load_factor
решение коллизий:
- метод открытой адресации: есть другая функция g(), которая говорит соответствующую другую ячейку для ячейки. усложняется поиск (тк нужно искать, пока не встретится пустая), удаление заменятся на флажок удаления
- метод кукушки: есть 2 хеш функции. вычисляем одну, вычисляем другую и если хоть на одном из мест свободно, то кладём туда, а если на обоих занято, то перекладываем ключ из одного на место по другой хеш функции
в std::undordered_map используется метод закрытой адресации/метод цепочек - в каждой вершине хранится связный список
нужно уметь итерироваться по unordered_map за O(кол-во добавленных элементов в unordered_map). решение - хранить value в односвязном списке
как устроена: помимо хеш таблицы есть односвязный список. в нодах хранится пара <key, value>, а также хеш. в ячейках хеш таблицы хранятся итераторы на список - указатель на конец предшествующего bucket’a - последовательности элементов с одинаковым хешом. ячейка, соответствующая первой ноде ведёт в фейковую вершину
- find: попадаем в хештаблицу по хешу, идём в бакет, скипаем, смотрим наш bucket. идём по списку, пока хеш не станет другим
- insert: если в хештаблице ещё не было такого хеша, то: смотрим на первую ноду и её хеш. идём в хештаблицу по этому хешу, понимаем, какая ячейка соответствует первому bucket’у. у этой ячейки обновляем поинтер с фейковой ноды (предпервой) на новую ноду. новая ячейка будет указывать на фейковую ноду, а фейковая нода на новую ноду (34.52:30) если был, то проходимся по bucket’у, если там есть такой же элемент, то ничего, а если нету, то вставляем в конец bucket’a
- erase: если мы удаляем последнюю ноду из бакета, то мы узнаём по ячейке из хеш таблицы предыдущий бакет. отвязываем ячейку от предыдущего бакета. идём в следующую от удаляемой ноды (новый бакет). идём в ячейку этого бакета, обновляем ей поинтер на предыдущий для удаляемой ноды бакет. удаляем ноду
- rehash: последовательный erase и insert по новому хешу (работает за O(n), но худший случай O(n^2) - если был один огромный бакет на n). не создаём новые пары ключ-значение => не инвалидируем указатели и ссылки на элементы. итераторы инвалидируются (почему в стандарте так написано - большой вопрос, но по факту под итератором просто рандомная нода). при рехеше не происходит вызов std::hash. тк мы помним все хеши в нодах, то мы просто берём индекс ячейки по новому модулю в msvc хранится двусвязный список, позволяющий делать erase безболезненно
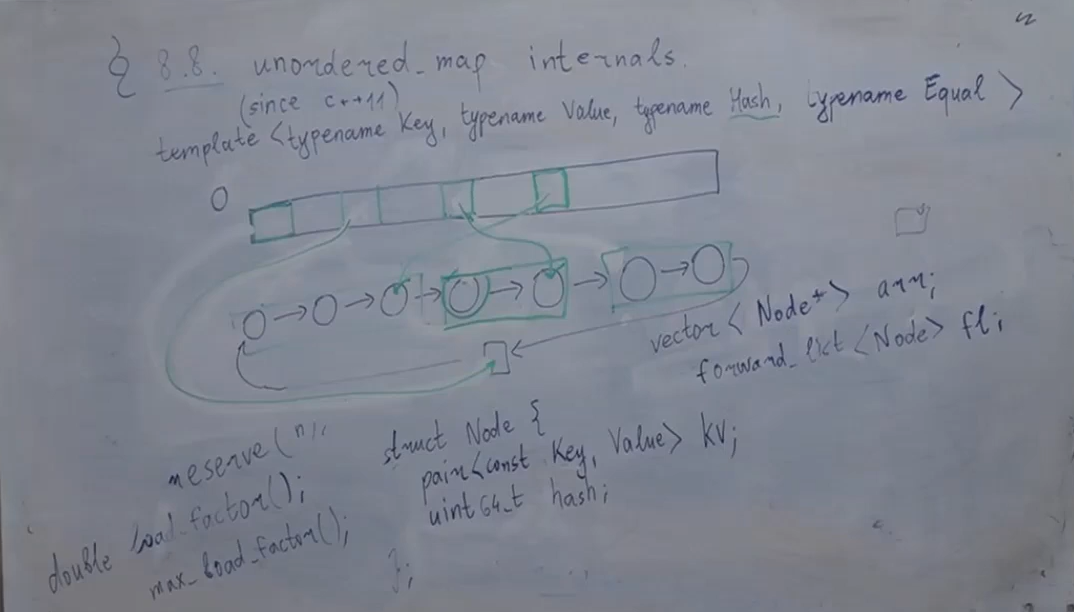
для своих типов можно доопределить в namespace std специализаю шаблона std::hash для своего типа
последний параметр - typename Equal - компаратор проверки на равенство. по умолчанию std::equal_to вызывающий == есть
- [], .at()
- .bucket_count()
каждая вставка элемента в std::list, std::set, std::map, std::unordered_map вызывает оператор new, если аллокатор стандартный